
Transformers Explained Simply: From Words to Intelligence (With an End-to-End Example)
A beginner-friendly, end-to-end guide to attention, Q-K-V, and how modern AI understands language.

Transformers are the foundation of modern AI systems like ChatGPT, image generators, and recommendation engines. But for many beginners, they feel abstract and difficult to understand.
In this post, we’ll break Transformers down step-by-step using a simple real-world example—so you can see exactly how data flows through the model.
By the end, you will understand:
What a Transformer is
How it processes text
What attention actually does
How input becomes output
How this works in real AI systems
The Problem — How does a model understand a sentence?
Consider this sentence:
“The cat sat on the mat because it was tired.”
Question:
What does “it” refer to?
A human instantly knows it refers to the cat.
But a machine must learn this relationship mathematically.
Older models processed words one-by-one and often forgot earlier context.
Transformers solve this using attention.
Visual: Transformer Overview
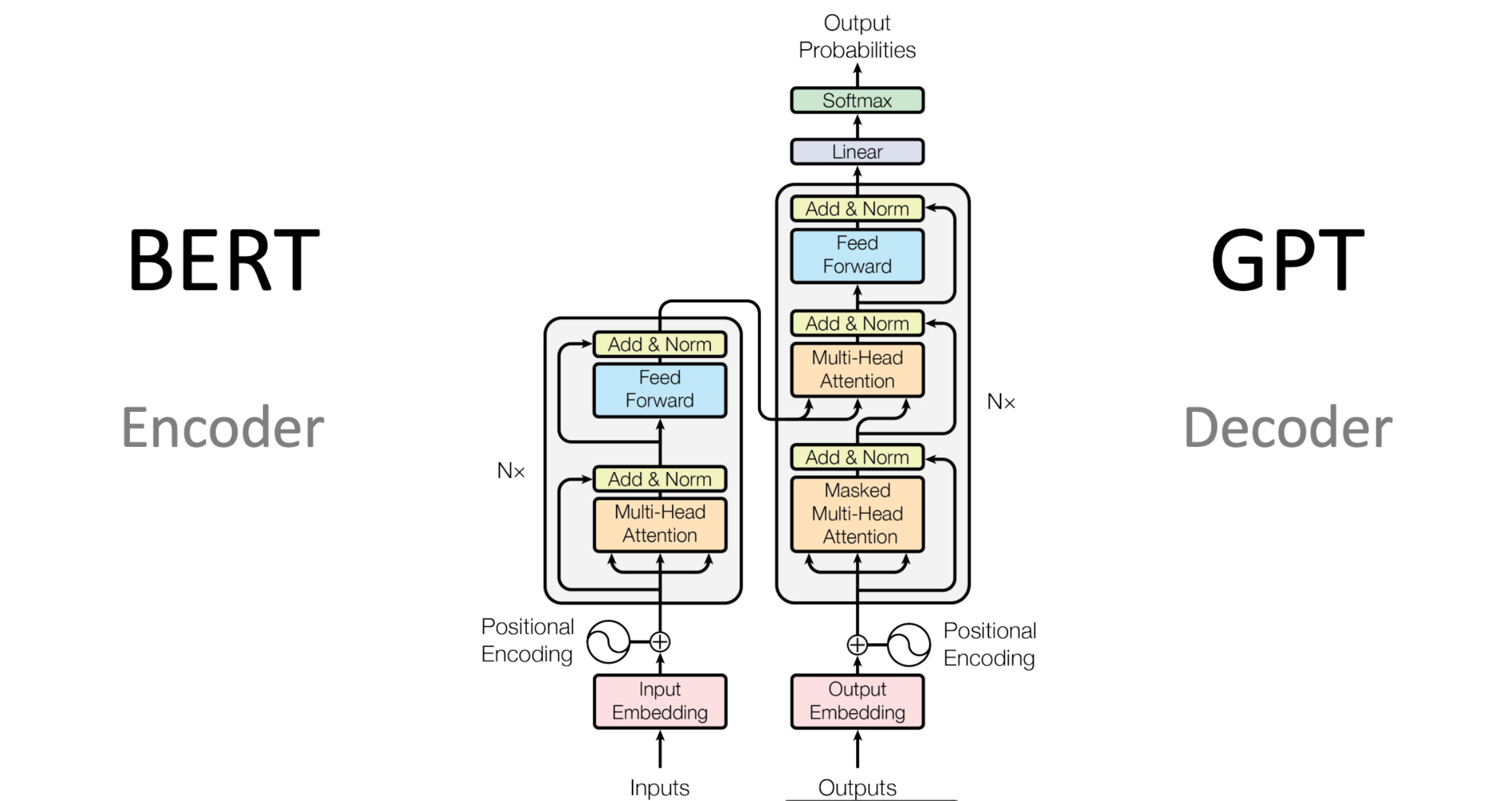



Step 1: Convert Words into Numbers (Tokenization)
Computers cannot understand words directly.
So the sentence becomes tokens:
[”The”, “cat”, “sat”, “on”, “the”, “mat”, “because”, “it”, “was”, “tired”]Each token is converted into a vector:
Example:
“The” → [0.21, -0.44, 0.90, ...]
“cat” → [0.67, 0.12, -0.33, ...]
“sat” → [-0.11, 0.89, 0.55, ...]This is called an embedding.
Think of embeddings as coordinates in meaning space.
Step 2: Add Position Information
Transformers process everything in parallel.
So we must tell the model the word order.
We add positional encoding:
cat + position(2)
sat + position(3)Now the model knows sequence structure.
Without positional
For example, these sentences would look identical to the model:
“Dog bites man”
“Man bites dog”
Both contain the same words, but the meaning is completely different.
Positional encoding adds information like:
dog + position(1)
bites + position(2)
man + position(3)This allows the Transformer to understand who did what, and in what order.
In simple terms:
Positional encoding tells the model where each word is located, so it can understand the correct sequence and meaning.
Step 3: Attention — The Core Innovation
This is the most important step.
Each word asks:
Which other words are important for understanding me?
Example:
Word: it
Attention might focus on:
cat ← high attention
mat ← low attention
tired ← medium attentionThis helps the model learn that it = cat

Step 4: Transformer Layer Processing
Each Transformer layer performs:
Attention
Neural network processing
Refinement of meaning
After multiple layers, the model builds deep understanding.
Example progression:
Layer 1: basic word relationships
Layer 4: grammatical structure
Layer 12: semantic meaning
Step 5: Generate Output
Now the model can perform tasks.
Example task: Predict next word
Input:
“The cat sat on the”Output prediction probabilities:
mat 0.72
floor 0.12
chair 0.08
roof 0.03Final output:
“The cat sat on the mat”End-to-End Flow Summary
Sentence
↓
Tokenization
↓
Embeddings
↓
Positional Encoding
↓
Self-Attention
↓
Transformer Layers
↓
Output PredictionThis entire process happens in milliseconds.
Real-World Example: Spam Detection
Input email:
“You won a free prize! Click here!”Transformer learns patterns like:
“free prize” → spam signal
“click here” → spam signal
Output:
Spam probability = 0.97Real-World Example: ChatGPT
Input:
Explain gravity simplyTransformer:
understands meaning
tracks context
predicts next words step-by-step
Output:
Gravity is the force that pulls objects toward each other.Intermediate: Why Transformers Are Powerful
Three key advantages:
1. Parallel processing
Much faster than older models
2. Long-range understanding
Connects distant words
Example:
The book that I bought yesterday was expensive.Understands relationships across distance.
3. Scales extremely well
More data + more compute = better intelligence
This enabled modern LLMs.
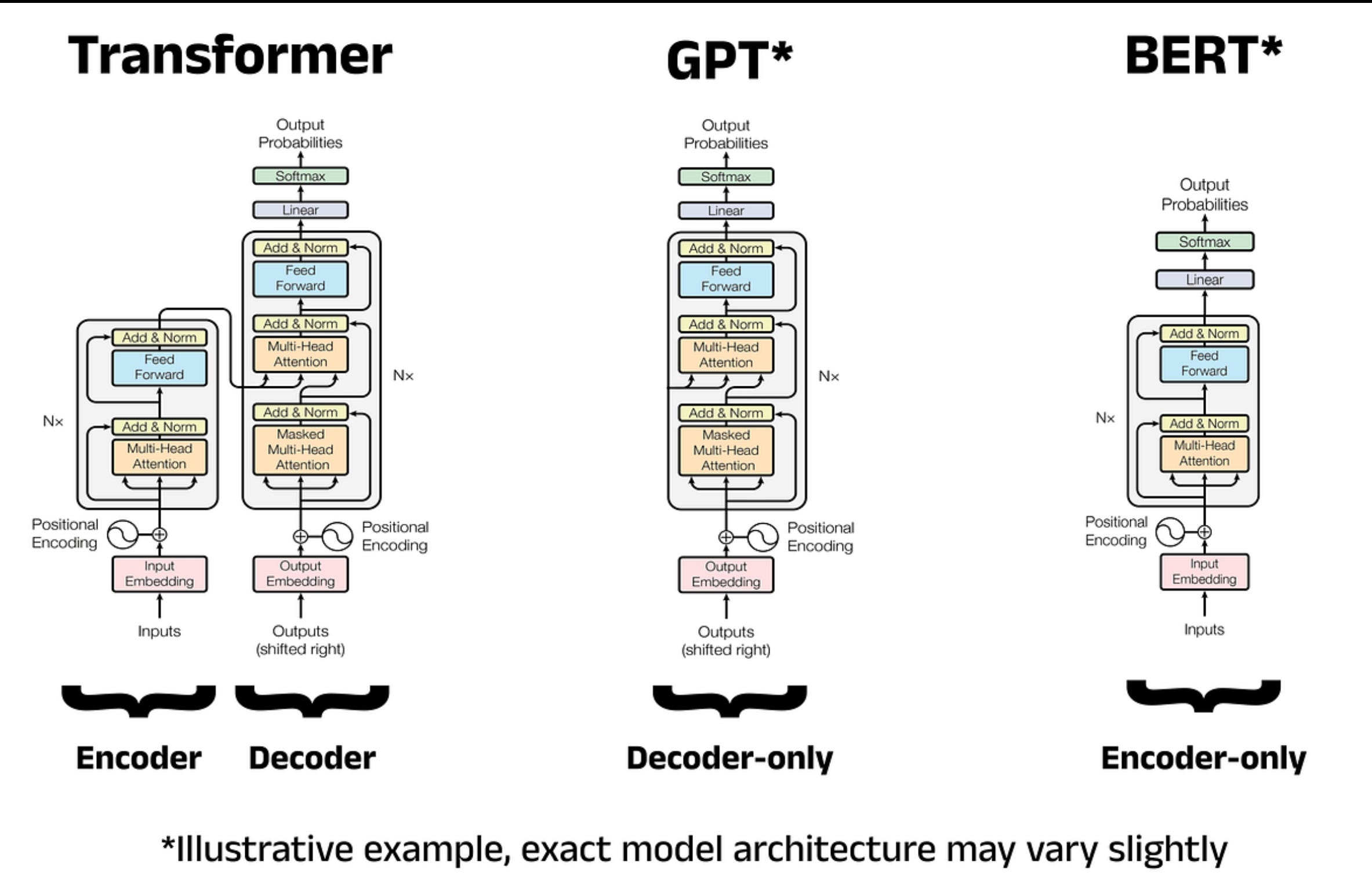
Practical Example with Numbers (Simplified)
Sentence:
cat eats fishEmbedding:
cat → [1.2, 0.3]
eats → [0.4, 1.1]
fish → [1.5, 0.9]Attention learns:
cat → related to eats
eats → related to fish
Final understanding:
Subject → Action → Object
Where Transformers Are Used Today
Nearly every modern AI system:
Text
Chatbots
Image generation
Search engines
Recommendation systems
Multimodal AI
Examples include:
ChatGPT
Stable Diffusion
Google Search ranking
Recommendation engine
Connecting Words Using Attention (The Core Idea of Transformers)
At the heart of every Transformer is a simple but powerful concept: attention connects words based on their relevance to each other.
Instead of reading a sentence one word at a time, the Transformer lets every word look at every other word and decide:
“Which words are important for understanding me?”
Simple Example
Sentence:
“The cat sat on the mat because it was tired.”
The word “it” must figure out what it refers to.
Using attention, the model evaluates relationships:

The model learns that “it” is strongly connected to “cat.”
This is how the model understands meaning.
Real-Life Analogy: Conversation in a Meeting 👥
Imagine a meeting with 10 people.
When someone says:
“He solved the problem.”
Everyone in the room quickly looks at the engineer who was working on it.
This “looking at the right person” is attention.
The Transformer does the same mathematically.
Think of Q, K, V as a simple search system inside the Transformer.
Query (Q) → what I am looking for
Key (K) → what each word offers
Value (V) → the actual information each word contains
The model compares Query with Keys to decide which Values to use.
Simple Real-Life Analogy
Imagine you go to a library.
You ask: “I want books about Deep Learning.” → this is your Query
Each book has a title/label → this is the Key
The actual content of the book → this is the Value
You compare your query with titles (Keys).
The most relevant books → you read their content (Values).
Transformer does exactly this with words.
Simple Sentence Example
Sentence:
“The cat drank milk because it was thirsty.”
We want to understand the word: “it”
Step 1: Query comes from the current word
For “it”
Query = representation of “it”Meaning: “What does it refer to?”
Step 2: Keys come from all words
Key(cat)
Key(milk)
Key(thirsty)
Key(drank)Each word says: “This is what I represent.”
Step 3: Compare Query with each Key

So cat is most relevant.
Step 4: Use the Value of the most relevant word
Each word has Value:
Value(cat) → animal information
Value(milk) → object informationFinal meaning of “it” becomes mostly influenced by:
Value(cat)So the model understands:
it = cat
Extremely Simple Formula
Attention score = Query × KeyThen:
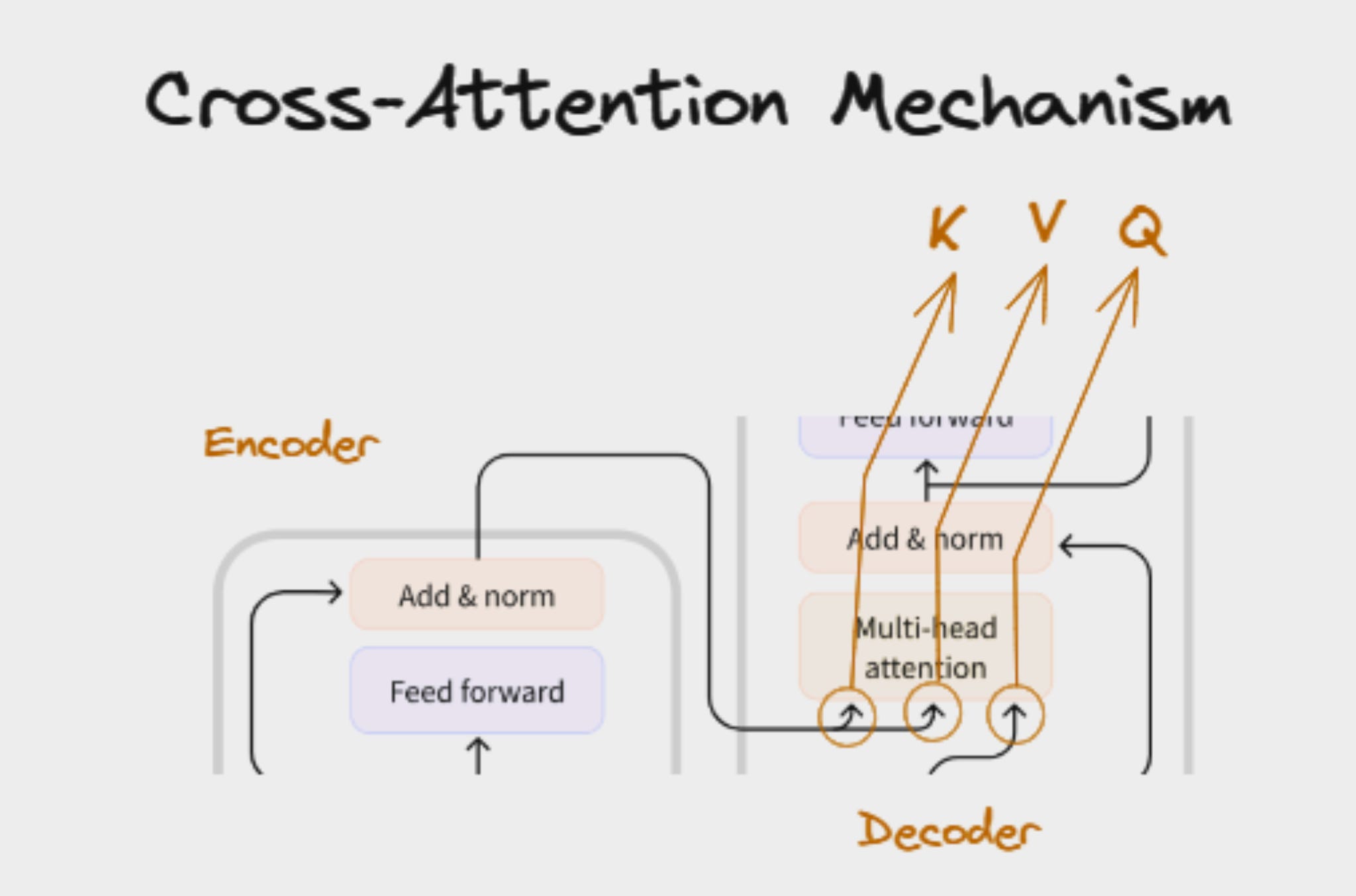
Output = weighted sum of ValuesVisualizing Flow (from your diagram)
In cross-attention:
Decoder word → Query
Encoder words → Keys and ValuesMeaning:
Decoder asks: “What part of the input should I focus on?”
Encoder responds with relevant information.
Even Simpler 1-Line Explanation
Query = question
Key = index
Value = answer
Tiny Numeric Example
Suppose:
Query(it) = [1, 0]
Key(cat) = [1, 0]
Key(milk) = [0, 1]Similarity:
it ⋅ cat = 1 (high)
it ⋅ milk = 0 (low)So model uses:
Value(cat)Difference: Self-Attention vs Cross-Attention
Self-Attention - Q, K, V all come from same sentence
Example: understanding a sentence
Cross-Attention - Q comes from decoder and K, V come from encoder
Example: translation, image captioning, diffusion models

Note: Cross-attention happens only in encoder–decoder architectures. Encoder-only (BERT) and decoder-only (GPT) models use self-attention.
One Powerful Intuition ⭐
Every word asks:
“Who in this sentence is important for me?”
Query asks
Keys answer relevance
Values provide information
Transformer as a Company Office 🏢
Imagine a company working on a project.
There is:
Manager → trying to complete a task
Employees → each has specific skills
Goal → manager must ask the right employees to finish the task
The manager does not ask everyone equally. The manager asks who is most relevant.
This is exactly how attention works.
Map Company Roles → Transformer Terms
CompanyTransformerManager asking questionQuery (Q)Employee skill descriptionKey (K)Employee actual work/knowledgeValue (V)Manager selecting employeesAttention
Example Scenario
Task:
Manager wants to build a website
Employees:
Alice → Frontend developer
Bob → Database engineer
Charlie → Graphic designer
Step 1: Manager creates a Query (What do I need?)
Manager thinks:
“I need someone for frontend UI”
This is the Query
Query = frontend requirementStep 2: Each employee presents their Key (What can I do?)
Employees respond:
Alice → Key = frontend skill
Bob → Key = database skill
Charlie → Key = design skillManager compares Query with each Key.
Step 3: Match score (Attention score)
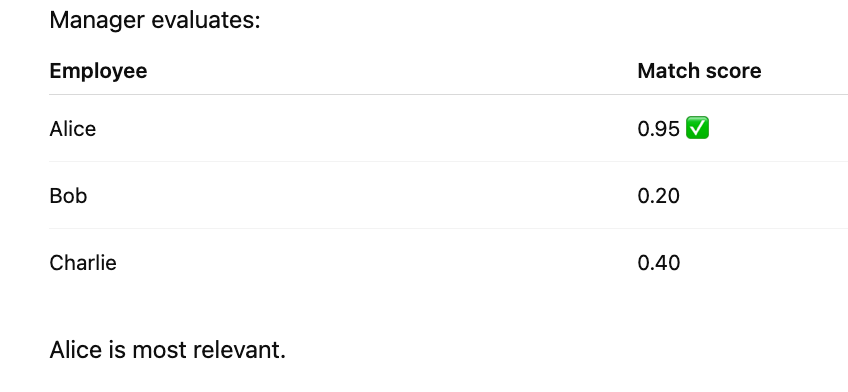
Step 4: Manager uses Value (Actual work)
Each employee also has Value:
Value(Alice) = frontend knowledge
Value(Bob) = database knowledgeManager mostly uses:
Value(Alice)Task gets completed correctly.
How this relates to words in a sentence
Sentence:
“The cat drank milk because it was thirsty.”
Goal: understand “it”
Manager = word it
Employees = all other words
Query(it) asks:
“Who am I referring to?”
Keys respond:
cat → strong match
milk → weak match
Manager chooses:
Value(cat)
So:
it = cat
Self-Attention in one sentence
Every word acts like a manager, asking:
“Which other words help me understand my meaning?”
Cross-Attention (Encoder–Decoder example)
Example: English → French translation
Encoder employees:
“cat”, “drank”, “milk”
Decoder manager generating word:
“chat” (French for cat)
Decoder asks:
Query → “Which English word corresponds to me?”
Keys → encoder words
Match → “cat”
Value(cat) used → generates “chat”
One-Line Memory Trick
Query = Manager question
Key = Employee skill label
Value = Employee actual knowledge
Attention = Manager choosing the right employee
How It Works Technically (Simplified)
Each word creates three vectors:
Query → What am I looking for?
Key → What do I represent?
Value → What information do I provide?
Then the model computes:
Attention Score = Query × KeyHigher score → stronger connection
Final representation becomes a weighted combination of important words.
Example with Numbers (Simplified)
Sentence:
cat eats fishAttention scores:

So eats connects strongly with both subject and object.
This helps the model understand the action.
Why This Is Powerful
Attention allows the model to:
Understand context
Resolve ambiguity
Learn relationships
Handle long sentences
Process everything in parallel
Without attention, modern AI like ChatGPT would not work.
One-Line Summary
Attention connects words by measuring how important they are to each other, allowing the Transformer to understand context and meaning.
Further Reading
The Illustrated Transformer — Jay Alammar https://jalammar.github.io/illustrated-transformer/
The Illustrated GPT-2
Attention Is All You Need (Original paper) -
Harvard Annotated Transformer
http://nlp.seas.harvard.edu/annotated-transformer/